 Evolution
Evolution
 Intelligent Design
Intelligent Design
New Peer-Reviewed Research Paper Corrects Misconceptions of Intelligent Design Critics about Genetic Algorithms
Douglas Axe recently discussed a new peer-reviewed research paper in BIO-Complexity by Winston Ewert, William Dembski, and Robert Marks. Titled “Climbing the Steiner Tree — Sources of Active Information in a Genetic Algorithm for Solving the Euclidean Steiner Tree Problem,” the paper furthers the efforts of the Evolutionary Informatics Lab to measure and quantify the extent to which intelligent agency influences the outcome of genetic algorithms.
According to the authors, “A genetic algorithm is a search algorithm that uses procedures that mimic natural selection and random mutation to determine which candidate solutions to try next.” Their research has developed the term “active information” to describe the information input by a programmer to help a search function find its target. The paper explains:
Genetic algorithms are widely cited as demonstrating the power of natural selection to produce biological complexity. In particular, the success of such search algorithms is said to show that intelligent design has no scientific value. Despite their merits, genetic algorithms establish nothing of the sort. Such algorithms succeed not through any intrinsic property of the search algorithm, but rather through incorporating sources of information derived from the programmer’s prior knowledge.
(Winston Ewert, William Dembski, Robert J. Marks II, “Climbing the Steiner Tree — Sources of Active Information in a Genetic Algorithm for Solving the Euclidean Steiner Tree Problem,” BIO-Complexity, Vol. 2012 (1).)
But what exactly does it mean to incorporate in the program sources of information derived from the programmer’s prior knowledge ? A primary purpose of the paper is to correct a common misconception held by many intelligent design (ID) critics.
While some claim genetic algorithms can solve complex problems, the paper suggests that “It may be, however, as advocates of intelligent design have argued, that such algorithms succeed by incorporating information about the target.” The paper observes that some programs, such as Richard Dawkins “METHINKGSITISLIKEAWEASEL” simulation, do in fact directly “work by sneaking the exact answer into the algorithm.” But others take a subtle approach, doing a less obvious job of front-loading the programmer’s prior knowledge in the genetic algorithm. Ewert and his co-authors explain:
Nevertheless, many simulations do not contain a fully articulated solution hidden behind lines of code that can be readily reconstructed by inspecting the program without running it. Proponents of intelligent design admit this possibility, arguing that such algorithms include information even when the solution has not been explicitly front-loaded into the simulation. The algorithm need not contain the explicit solution that is later found by running the algorithm. Rather, its code is frontloaded with specialized information for how to find that solution. Instead of the explicit answer, the means by which the eventual product can be found is front-loaded.
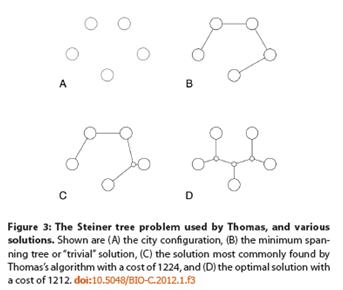
They observe that ID critic David Thomas has cited genetic algorithms as a method of solving the Steiner tree problem — a classical mathematical/real world problem where you have multiple destinations and must find the shortest — or most cost effective — route to reach all those destinations. Companies planning efficient delivery routes, or cities trying to build roads or highways to efficiently reach multiple neighborhoods, must solve Steiner tree problems.
Before getting into this in too much detail, it’s worth noting who Thomas is and why he’s worth responding to. Thomas is president of New Mexicans for Science and Reason and a fellow of the Committee for Skeptical Inquiry. But he also has legitimate academic credentials. He is a physicist and mathematician, and as recently as last year worked as a scientist and programmer at the Incorporated Research Institutions for Seismology (IRIS) Program for Array Seismic Studies of the Continental Lithosphere (PASSCAL) Instrument Center, affiliated with the New Mexico Institute of Mining and Technology, where he also teaches classes. Thomas has boasted:
If you contend that this algorithm works only by sneaking in the answer (the Steiner shape) into the fitness test, please identify the precise code snippet where this frontloading is being performed
However, the BIO-Complexity authors also observe that Thomas misunderstands the nature of ID claims about the workings of genetic algorithms. According to the paper, “Thomas is under the misapprehension that intelligent design advocates claim that the actual answer is encoded into the algorithm,” whereas “This is not in fact what intelligent design advocates claim.” Rather, the claim is that programmers can import active information into programs in more subtle ways, using prior knowledge to fine-tune the algorithm to find the solution. While this might be a good programming strategy, it is nothing like the blind and unguided process of Darwinian evolution:
Rather, we say that success is due to prior knowledge being exploited to produce active information in the search algorithm. Although the code does not include the actual Steiner shape, it does include a tuned algorithm for how to find the Steiner shape. … It should be emphasized that fine-tuning genetic algorithms is common practice. There is nothing unreasonable about the practice. It is in fact necessary, and very useful for producing results from genetic algorithms. Problems arise when attempting to draw inference from a fine-tuned simulation to non-finetuned biological reality. We will demonstrate that the fine-tuning is necessary to the success of the algorithm; consequently, the results cannot be used to defend the success of search algorithm in the absence of fine-tuning.
Using their methods of measuring active information, the authors determine that Thomas’s Steiner tree algorithm uses multiple sources of prior knowledge given by the programmer:
Various other genetic algorithms that solve Steiner tree problems clearly and openly make use of theoretical insights into the Steiner tree problem to assist in the search. Thomas indicates that he does not make use of such knowledge, but this is not the case. The distribution of the number of interchanges has been tweaked so that the algorithm focuses on solutions with the correct number of interchanges. The initial population is generated such that the interchanges are located where they are more likely to be useful. The strength of selection has been increased by a parameter to counteract the small range of interesting fitness values. The crossover method and genome structure assist in finding the solution. All of these introduce active information; they are exploiting prior knowledge about the problem. Thomas’s algorithm does make use of far less prior knowledge than the other Steiner tree algorithms and as a result is only able to solve problems an order of magnitude smaller.
They conclude that intelligence is necessary to solve problems like the Steiner tree:
[W]e have shown that the search algorithm proposed as an example of the power of natural selection to generate information from scratch in fact demonstrates the abilities of humans to devise genetic algorithms that draw on existing information. Thomas has failed to demonstrate the abilities of natural selection left to itself. In order to demonstrate the abilities of natural selection, it would be necessary to avoid making any decisions in the development of the genetic algorithm that deliberately assist in finding the solution. Only a teleological process guided by some form of intelligence can function in this way. Insofar as simulations of evolution make use of prior knowledge, they are not simulations of Darwinian evolution in any meaningful sense.