 Intelligent Design
Intelligent Design
Peer-Reviewed Paper: Development Needs Ontogenetic Information that Cannot Arise from Neo-Darwinian Mechanisms
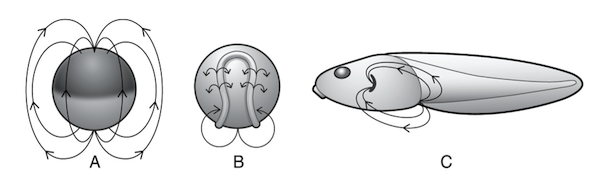
Endogenous electric fields in Xenopus embryos at progressive stages of development, from Wells (2014).
Jonathan Wells has published a new peer-reviewed scientific paper in the journal BIO-Complexity, “Membrane Patterns Carry Ontogenetic Information That Is Specified Independently of DNA.” With over 400 citations to the technical literature, this well-researched and well-documented article shows that embryogenesis depends on crucial sources of information that exist outside of the DNA.
This ontogenetic information guides the development of an organism, but because it is derived from sources outside of the DNA, it cannot be produced by mutations in DNA. Wells concludes that because the neo-Darwinian model of evolution claims that variation is produced by DNA mutations, neo-Darwinism cannot account for the origin of epigenetic and ontogenetic information that exists outside of DNA.
As Wells observes, many biologists going back decades have accepted the “central dogma” of molecular biology — without qualification — which claims genes encoded by DNA entirely determine an organism. This view essentially says “DNA makes RNA makes protein makes us.” He writes:
The emphasis on genetic programs owes much to evolutionary theory — specifically, to the modern synthesis of Darwinian evolution and Mendelian genetics. According to the modern synthesis, new heritable variations originate in genetic mutations. In a 1970 interview, Monod said that with the establishment of the central dogma, “and the understanding of the random physical basis of mutation that molecular biology has also provided, the mechanism of Darwinism is at last securely founded”.
No one doubts that DNA encodes RNA, and RNA is translated to make proteins, but it’s a lot more complicated than just that. Many other sources of information enter the process along the way that may not stem directly from information encoded in DNA. The idea that the central dogma is incomplete is really not controversial these days, with so much research showing how epigenetic mechanisms are vital for biological function. However, many still think that at base, all the information you need to build an organism is in the DNA. Is that true?
For example, Wells finds that some of the basic axes of organismal development are in place before the initiation of developmental gene regulatory networks (dGRNs), some of the earliest expressions of genes during development: “Spatial anisotropies precede — and are causally upstream of — the embryo’s dGRNs.” Again, it’s not that genes aren’t important and crucial for organismal development. Rather, Wells argues that they can’t be everything:
Embryo development (ontogeny) depends on developmental gene regulatory networks (dGRNs), but dGRNs depend on preexisting spatial anisotropies that are defined by early embryonic axes, and those axes are established long before the embryo’s dGRNs are put in place.
He goes on to identify crucial sources of ontogenetic information that exists outside the DNA. Specifically, information can be stored in biological membranes that is crucial for the development of an organism — also called ontogeny:
So biological membranes are patterned in complex ways. Those patterns serve important functions in cells, tissues and embryos. The following sections summarize the roles of plasma membrane patterns in (a) providing targets and sources for intracellular transport and signaling, (b) regulating cell-cell interactions by means of a “sugar code,” and (c) generating endogenous electric fields that provide three-dimensional coordinate systems for ontogeny.
Let’s look at these sources of information, briefly.
Intracellular Targets and Signaling
The locations of mRNAs is important in many cells during development for expressing genes in certain locations of cells, and for determining the cells’ spatial axes. So how do mRNAs end up in the right location? Wells explains that cells use a “zip code” system to help direct molecules to the proper locations:
The localization of mRNAs commonly depends on specific sequences in their untranslated regions that have been called “zip codes”. Like postal zip codes, such sequences identify the “addresses” in the cell to which the mRNAs are to be sent. Like a postal zip code, however, an mRNA zip code is meaningless unless it matches a pre-existing address — that is, a target.
Evidence from a variety of cells suggests that mRNA localization requires the binding of a protein to the zip code to form a ribonucleoprotein particle (RNP); the combination is then transported to its destination.
However, Wells recognizes that the destinations for these “zip codes” are not encoded by the DNA:
Like zip codes themselves, however, zip code-binding proteins do not specify the destination. Using the postal code metaphor, zip code-binding proteins could be likened to cargo containers, cytoskeletal motor molecules to delivery trucks, and the cytoskeleton to the highway system on which the trucks travel. But destinations for intracellular transport — like the geographical addresses in a postal delivery system — must also be specified.
In some cases, destinations might be specified by the spatial arrangement of microtubules; in the postal metaphor, packages could be dispatched on a particular highway and then carried to the end of the road and simply dropped off. In some cases, however, destinations are known to be specified by targets in the form of membrane-bound proteins that respond to extracellular cues.
In other words, for the “zip codes” to function properly, there must be destinations, but those destinations are specified outside of the DNA.
The Sugar Code
Another non-DNA form of information Wells identifies is the “sugar code,” determined by complex patterns of sugar molecules, called glycans, on membrane surfaces. These molecules can carry high amounts of information since “carbohydrates can form branching chains that are far more elaborate than linear chains of nucleotides and amino acids.” Wells explains:
While the four nucleotides in the genome can form a maximum of 46 ? 4 x 103 hexanucleotides, and the twenty amino acids in the proteome can form a maximum of 206 ? 6 x 107 hexapeptides, the dozen or so monosaccharides in the “glycome” can theoretically form more than 1012 hexasaccharides. Clearly, the information-carrying capacity of the “glycome” far exceeds the combined capacities of the genome and the proteome. The information carried by the glycome has been called the “glycocode” or “sugar code”.
[…]
The sugar code can be “interpreted” by proteins called lectins. Unlike antibodies, lectins are not produced by the immune system, and unlike enzymes they do not catalyze biochemical reactions, but like antibodies and enzymes they “recognize” specific three-dimensional structures of other molecules. They do this by means of “carbohydrate recognition domains”.
So what can the sugar code do exactly?
Studies using monoclonal antibodies have shown that cell-surface glycans in early mouse embryos change in a highly ordered and stage-specific manner; the data suggest that they mediate cellular orientation, migration, and responses to regulatory factors during development.
Wells explains that “These patterns play important roles in development.” But of course, these patterns are determined by arrangements of complex sugars, and are not encoded by information in DNA.
Endogenous Electric Fields
This next source of extra-genetic information — electric fields in embryos — might at first blush sound a bit weird, but it is well established in the peer-reviewed literature and in the field of developmental biology. Wells explains:
It has long been known that probably all living cells (not just nerve and muscle cells) generate electric fields across their membranes. In animal cells, a sodium-potassium pump in the membrane utilizes energy from ATP to move three sodium ions out of the cell while taking in two potassium ions. This raises the intracellular concentration of potassium ions, which corrects the imbalance by flowing out of the cell through ion-selective channels in the membrane. The combined action of sodium-potassium pumps and potassium “leak” channels makes the interior of the cell electrically negative with respect to the exterior. The resulting voltage difference across the membrane is called the “membrane potential”.
These electric fields have been measured around cells and within embryos, and it turns out that they themselves are a form of information that can influence development. How so? Wells writes:
One way might be to direct cell movements. For over a century electrically guided locomotion, called “galvanotaxis,” has been observed in cells from a variety of organisms in the presence of artificially applied electric fields. … Applied electric fields can also affect neural networks. Nerve cells establish contact with each other by extending projections called neurites. When embryonic chick ganglia were placed in DC electric fields ranging from 70?140 mV/mm, their neurites grew faster toward the cathode than the anode. Embryonic Xenopus neurons reportedly do the same in fields as low as 7 mV/mm.
Wells further observes that “The most compelling evidence that ion currents, transmembrane voltage potentials and EEFs play significant roles in ontogeny comes from artificially disrupting them in vivo and then observing the effects of their disruption on morphogenesis.”
Where Does the Information Come From?
After reviewing these sources of information, Wells concludes that they lie outside the control of DNA:
So membrane patterns — the three-dimensional arrangements of membrane-associated proteins, lipids and carbohydrates, as they change over time — carry essential ontogenetic information. Yet (as I demonstrate below) the information carried by membrane patterns cannot be reduced to sequence information in DNA, for at least two reasons. First, the vast majority of proteins in eukaryotes are not completely specified by DNA sequences. Second, even if DNA sequences completely specified all proteins, DNA would not specify their spatiotemporal arrangements in membranes.
As to the first point, Wells recognizes that various well-established processes like alternative splicing and RNA editing often determine the amino acid sequence of proteins. As to the second point, he observes:
Even if DNA sequences uniquely specified the molecular structures of proteins, DNA would not specify the spatial distribution of proteins in the plasma membrane. Some membrane patterns are templated by the membranes from which they are derived, with proteins from the cell interior being incorporated during membrane growth only if they match the existing matrix.
Indeed, Wells notes that these membranes are required for producing new membranes, and “If any type of genetic membrane were lost, it could probably not be regenerated from its constituent molecules — even if all the genes encoding its proteins and lipid-synthesizing machinery remained — because the requisite spatial pattern would be gone.” So this is another crucial source of information that exists outside of the DNA.
What does all this mean for neo-Darwinism? For one thing, it shows that the central dogma is woefully incomplete:
Membrane patterns are not specified by DNA sequences. First, DNA sequences only partially specify RNAs and proteins. After transcription, many RNAs undergo alternative splicing and/or editing, so thousands of different mRNAs can be generated from a single DNA sequence. After translation, some proteins are edited to produce different amino acid sequences, and many proteins with similar amino acid sequences can adopt more than one folded structure — or they are intrinsically disordered. Furthermore, most eukaryotic proteins are post-translationally modified by glycosylation. Given the enormous number of possible glycan structures, a protein can be modified in trillions of possible ways. If “makes” is taken to mean “specifies,” then “DNA makes RNA makes protein” fails at each step.
Obviously, Wells isn’t saying that DNA is unimportant:
Of course, no one denies that DNA is essential for ontogeny, and that DNA mutations can affect phenotypic traits. Furthermore, population genetics may be useful for tracing lineages within existing species. But since the ontogenetic information in an embryo far exceeds that in its DNA, evolution must necessarily involve far more than changes in gene frequencies.
However, population genetics — the mathematical basis for modern neo-Darwinian theory — is predicated upon the view that traits are encoded in DNA, and mutations in DNA produce new traits for natural selection to act upon. But since many traits aren’t determined by DNA, mutations in DNA cannot produce those traits. The very basis of the theory falls apart. Wells explains:
As we have seen, however, the idea that embryo development is controlled by a genetic program is inconsistent with the biological evidence. Embryo development requires far more ontogenetic information than is carried by DNA sequences. Thus Neo-Darwinism is false.
This is cutting-edge biology — but Wells grounds it in literally hundreds of citations to the peer-reviewed literature. Papers like this show that when freed from the “central dogmas” of neo-Darwinian evolution, a theory of intelligent design can open up promising and fruitful avenues of research and thinking in biology.