 Intelligent Design
Intelligent Design
 Life Sciences
Life Sciences
Astrobiologists Offer an “Information-Based View of the Biosphere”

Visualize an exoplanet far away: dynamic, comfortable, yet lifeless. It has water, plate tectonics, volcanoes, an atmosphere, and all the ingredients for life — but no life. What would be the primary factor distinguishing it from Earth? A paper in PLOS Biology suggests that its chief drawback, all things being equal, would be a lack of complex specified information.
A Remarkable Paper
In this remarkable paper, Landenmark, Forgan, and Cockell of the United Kingdom Centre for Astrobiology at the University of Edinburgh attempt “An Estimate of the Total DNA of the Biosphere.” The results are staggering:
Modern whole-organism genome analysis, in combination with biomass estimates, allows us to estimate a lower bound on the total information content in the biosphere: 5.3 × 1031 (±3.6 × 1031) megabases (Mb) of DNA. Given conservative estimates regarding DNA transcription rates, this information content suggests biosphere processing speeds exceeding yottaNOPS values (1024 Nucleotide Operations Per Second). Although prokaryotes evolved at least 3 billion years before plants and animals, we find that the information content of prokaryotes is similar to plants and animals at the present day. This information-based approach offers a new way to quantify anthropogenic and natural processes in the biosphere and its information diversity over time.
As a side note, they never explain their odd distinction between “natural” and “anthropomorphic” (are humans not natural?). Their last sentence just says, “This approach may help us understand the changing complexity of the biosphere over time and to predict in new ways, both anthropogenic and natural, future changes in the biosphere.” Apparently even typical astrobiologists have an intuitive sense of human exceptionalism.
But returning to the topic of interest, let’s ponder the scale of this information content and processing speed. A yottaNOPS is a lotta ops! Each prefix multiplies the prior one by a thousand: kilo, mega, giga, tera, peta, exa, zetta, yotta. A “yottabase” doesn’t even come close to the raw information content of DNA they estimate: 1031 megabases. That’s the same as 1037 bases, but a yottabase is only 1024 bases (a trillion trillion bases). This means that the information content of the biosphere is 50 x 1013 yottabases (500 trillion yottabases). They estimate that living computers perform a yottaNOPS, or 1024 nucleotide operations per second, on this information.
You Can Pick Yourself Off the Floor Now
This is a profound indication of the priority of information to life. It’s not just the rocks, water, and elements that characterize Earth, but the astonishing amount of information and information processing that goes on all around us. That’s why we have fish, birds, insects, bacteria, mammals, and people.
But how does a scientific materialist account for this incredible computing power? Let’s see what the three astrobiologists do with it. First, they keenly recognize the similarity of DNA processing to computer processing:
Biodiversity and habitat loss is recognised as a global issue. In response, substantial research effort has been invested in genome sequencing and the preservation of vulnerable species and habitats. However, despite these remarkable advances, to our knowledge, there is still no estimate of the total information content of the biosphere. Using available DNA sequencing and genome data, combined with large-scale surveys of biomass, we present an alternative way of quantifying and understanding biodiversity. This is accomplished by adopting an information view of biodiversity, in which the total amount of information in the biosphere is represented by the available amount of DNA (Fig 1). In this way, the biosphere can be visualised as a large, parallel supercomputer, with the information storage represented by the total amount of DNA and the processing power symbolised by transcription rates. In analogy with the Internet, all organisms on Earth are individual containers of information connected through interactions and biogeochemical cycles in a large, global, bottom-up network. By combining data on genome size, spatial diversity, and mass from different prokaryotes, eukaryotes, and the viruses, we estimate the total biomass for each group and then derive a first-order, lower-bound approximation for the total DNA content of each group.
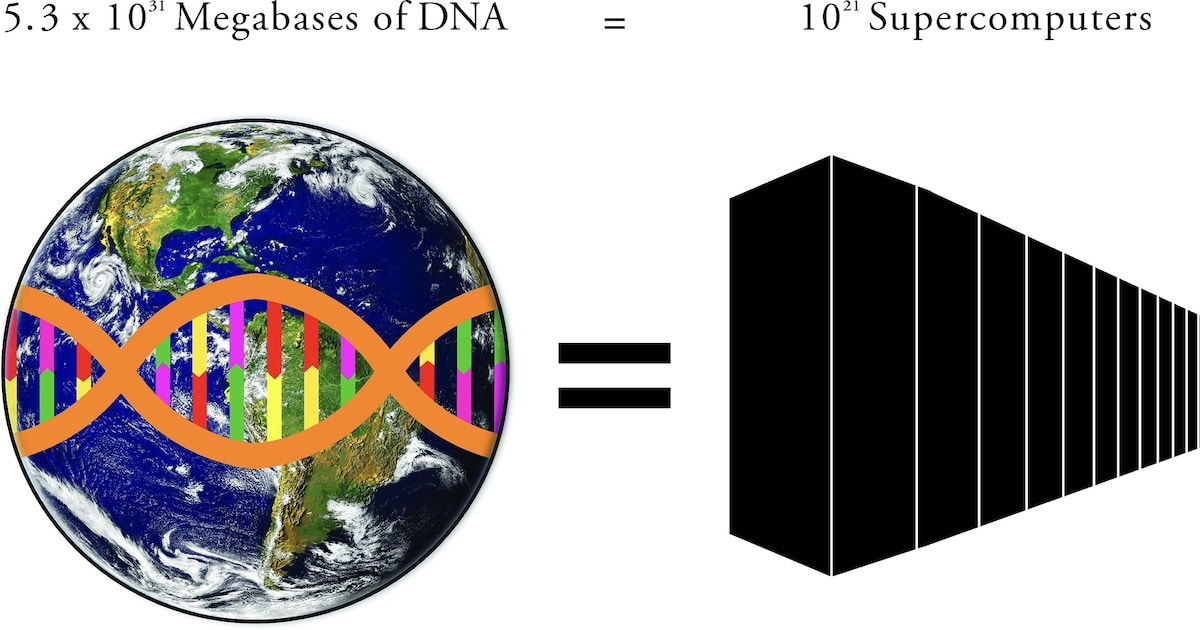
Figure 1 in their paper, reproduced above, illustrates their main point, summarized by the caption: “Storing the total amount of information encoded in DNA in the biosphere, 5.3 × 1031 megabases (Mb), would require approximately 1021 supercomputers with the average storage capacity of the world’s four most powerful supercomputers.”
How much land surface would be required for 1021 supercomputers (a “zetta-computer”)? The Titan supercomputer takes up 404 m2 of space. If we assume just 100 m2 for each supercomputer, we would still need 1023 square meters to hold them all. Universe Today estimates the total surface of Earth (including the oceans) at 510 million km2, which equates to 5.1 x 1014 m2. That’s 9 orders of magnitude short of the zetta-computer footprint, meaning we would need a billion Earths to have enough space for all the computers needed to match the equivalent computing power life performs on DNA!
A Very Thin Veneer
That calculation included the ocean surface for comparison, since much life is in the ocean. Although life occupies multiple levels in the ocean, land, and air, the biosphere represents a very thin veneer of the Earth’s overall volume. It’s certainly unreasonable to expect every square meter of a planet’s surface to contain computers; where would the power come from? It only requires one planet — not a billion — to hold all the DNA processors, because life is so miniaturized and efficient, using energy from the sun.
The implications of this “information-based view of the biosphere” are not lost on the astrobiologists. They dismiss Gaia but leave a door open for intelligent design:
We note that the approach that we propose here (and the analogy of supercomputers) does not necessarily imply a global, Gaia-like superorganism. We merely observe that ultimately all organisms interact with each other and the environment. Thus, the information being processed in the biosphere is interlinked in a large mass of organisms, however one chooses to conceptualise this. It does not have to be considered as a single, self-regulating organism. The manner in which the total information in the biosphere is processed, and the degree to which it is coordinated and interlinked in feedback processes, is another matter, but one that could be investigated using an information-based approach.
The rest of the paper discusses how the researchers arrived at their numbers and how the values might have varied over time. (They estimated that the information content in prokaryotes, the simplest organisms, is similar to that of higher organisms — within two orders of magnitude, which they found surprising.) They also include caveats about assumptions and uncertainties in their measurements and offer suggestions for answering future questions. The whole paper is very interesting.
But the Damage Is Done
Even if their estimates need to be revised by a terabase or two someday, they have made it clear that our biosphere is awash in information. Though clearly evolutionists, they have present a significant challenge to scientific materialism to account for all this processing power. Simultaneously, they demonstrate the fruitfulness of an information-based approach to the investigation of life.
This article was originally published in 2015.
