 Evolution
Evolution
 Intelligent Design
Intelligent Design
The DNA Replisome: A Paradigm of Design
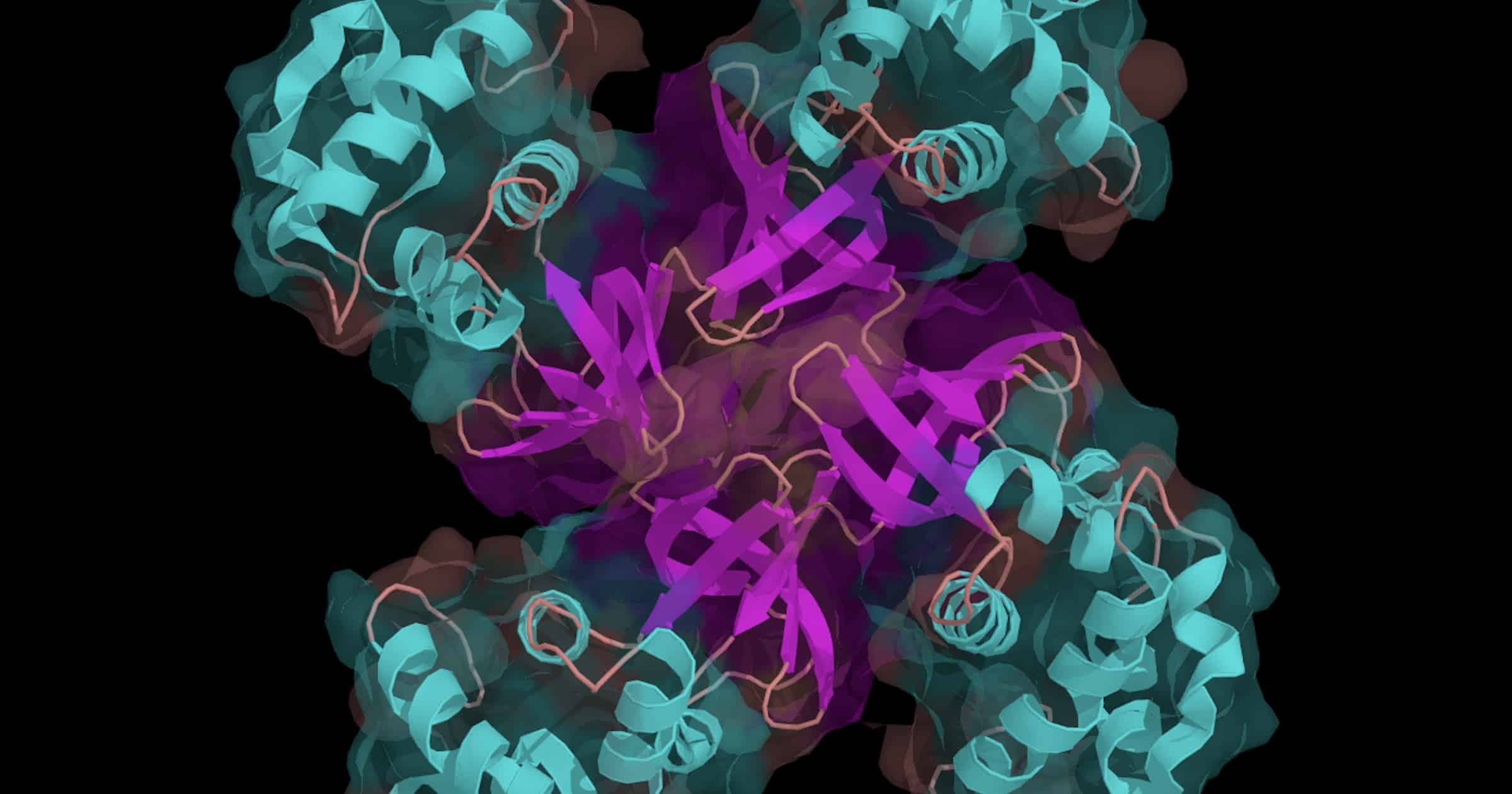
The DNA replisome is one of the most remarkable molecular machines, involving a complex of different proteins, each of which is very specifically crafted to fulfill its role in the process of replicating the genome in preparation for cell division. The rate of DNA replication has been measured at a whopping 749 nucleotides per second1 and the error rate for accurate polymerases is believed to be in the range of 10-7 and 10-8, based on studies of E. coli and bacteriophage DNA replication.2
One of the best animations of this incredible process is this one by Australian animator Drew Berry:
It is difficult to look at an animation such as this (which is drastically over-simplified) and not come away with the strong intuition that such an intricately choreographed machine is the product of masterful engineering. Stable and functional protein structures are astronomically rare in combinatorial sequence space, and DNA replication requires many of them. But not just any old stably folding proteins will do. These proteins have to be crafted very particularly in order to perform their respective jobs. Indeed, when one focuses on specific proteins, it takes the design intuition to new heights. For example, see these beautiful animations of topoisomerase, helicase, and DNA polymerase. One paper summarizes the engineering prowess of DNA replication thus:
Synthesis of all genomic DNA involves the highly coordinated action of multiple polypeptides. These proteins assemble two new DNA chains at a remarkable pace, approaching 1000 nucleotides (nt) per second in E. coli. If the DNA duplex were 1 m in diameter, then the following statements would roughly describe E. coli replication. The fork would move at approximately 600km/hr (375 mph), and the replication machinery would be about the size of a FedEx delivery truck. Replicating the E. coli genome would be a 40 min, 400 km (250 mile) trip for two such machines, which would, on average make an error only once every 170 km (106 miles). The mechanical prowess of this complex is even more impressive given that it synthesizes two chains simultaneously as it moves. Although one strand is synthesized in the same direction as the fork is moving, the other chain (the lagging strand) is synthesized in a piecemeal fashion (as Okazaki fragments) and in the opposite direction of overall fork movement. As a result, about once a second one delivery person (i.e. polymerase active site) associated with the truck must take a detour, coming off and then rejoining its template DNA strand, to synthesize the 0.2km (0.13 mile) fragments.3
Irreducible Complexity on Steroids
DNA replication is an example of what we might call “irreducible complexity on steroids.” Genome duplication is a prerequisite of differential survival, which is necessary for the process of natural selection to even work. Thus, one can hardly appeal to natural selection to account for the origins of DNA replication without assuming the existence of the very thing one is attempting to explain. It is difficult to envision a viable replication system that is simpler than the DNA replisome shown in the animation above. Though the RNA world scenario (which maintains that RNA-based life predates life based on DNA and proteins) is a popular hypothesis, problems abound for this scenario, as has been discussed many times here at Evolution News and in various other publications (e.g., Stephen Meyer’s book, Signature in the Cell, Chapter 14). For example, one of the foremost challenges is the inherent instability of RNA (being single stranded, and possessing an additional 2’ OH group, rendering it prone to hydrolysis). RNA polymers are therefore extremely unlikely to have survived in the early Earth environment for long enough to be of much value. Second, when RNA forms complementary base pairs to fold back on itself, part of the molecule no longer presents an exposed strand that can serve as a template for copying. Thus, there is a physical limitation on the capability of RNA to self-replicate.
A further reason why the DNA replication machinery exhibits irreducible complexity on steroids is that, being so primitive, it is far more difficult to envision any kind of co-optation scenario than it would be for a system that arose much later, such as bacterial flagella. With the flagellum, one can at least point to alternative functions that might be performed by a number of the flagellar components (such as the Type III Secretion System). However, with DNA replication, it is unclear what other systems any of the components might be co-opted from – since any other system would need to have arisen after the origins of DNA replication.
An even more striking enigma is that, across the three domains of life, the key enzymes (in particular, the replicative polymerases) are not homologous, which has led to the suggestion that DNA replication may have arisen more than once independently.4,5 This observation sits more comfortably on a design paradigm than on one committed to naturalism.
Which Components Are Essential for DNA Replication?
What protein components that are involved in DNA replication are indispensable for function? First, there is the DNA polymerase that actually performs the copying of each strand. Without it, no replication would take place at all. But the DNA polymerase is unable to begin replication without the presence of a free 3’ OH (hydroxyl) group. Thus, another enzyme — a form of RNA polymerase called a primase — creates a short RNA fragment (called a primer) from which the DNA polymerase can extend (unlike DNA polymerase, the primase does not require the presence of a free 3’ OH group). Thus, in the absence of the primase enzyme, no RNA primers would be laid down on either the leading or lagging strand, and DNA replication would be unable to commence. Furthermore, the DNA polymerase itself has to be attached to the DNA by a ring-shaped protein known as a sliding clamp (which prevents it from falling off the DNA template strand). But the sliding clamp cannot directly attach to the DNA on its own. Instead, a protein complex called the clamp loader mediates the loading of the sliding clamp onto the DNA at the replication fork, utilizing the energy from ATP hydrolysis to open the sliding clamp ring and load it onto the DNA. In the absence of the sliding clamp or clamp loader, the DNA polymerase would frequently fall off the DNA template, rendering it extremely inefficient.
Of course, the replication process cannot begin unless the DNA double helix is unzipped, and this is accomplished by the enzyme helicase, which breaks the hydrogen bonds along the DNA molecule, thereby opening up and exposing the two strands for replication by the polymerase. In its absence, the DNA polymerase will stall, unable to separate the strands that lie ahead.
Even with the helicase enzyme separating the two strands, the strands are likely to reanneal during the copying process. Enter the single-stranded binding proteins which bind to the exposed DNA strands, preventing them from re-annealing during copying. Without them, the DNA strands would bind together again before they were able to be copied.
The topoisomerase enzymes are necessary for removing supercoils that are induced by the torsional stress. They do so by cutting one strand, passing the other strand through the gap, and then resealing the break. In the absence of the topoisomerase enzymes, the DNA would eventually break, thereby hindering the DNA replication process.
Because of the anti-parallel nature of DNA (and the fact that the DNA polymerase can only replicate in a 5’ to 3’ direction), one strand, the lagging strand, has to be replicated backwards (in order for the replication fork to move in a single direction). This is done discontinuously in small sections. RNA primers are laid down by primase, and from those are synthesized short fragments of DNA known as Okazaki fragments. The RNA primers are then removed and replaced with DNA, and the Okazaki fragments are stitched together by the enzyme ligase. We have already discussed the necessity of the primase enzyme for synthesizing RNA primers. It may be added that, in the absence of the RNA excision enzymes (which remove the RNA primers), the RNA fragments would remain covalently attached to the newly replicated fragments of DNA. Moreover, in the absence of ligase (which links the Okazaki fragments together), the newly replicated strands would remain as fragments.
If the removal of any of the aforementioned components would render the DNA replication machinery non-functional, how could such a system come about through an undirected Darwinian step-wise pathway, preserving selective utility at every step along the way? Whatever process produced the DNA replisome had to know where the target was. Such a cause would have to be teleological in nature.
A Paradigm of Design
The DNA replication machinery represents one of the most extraordinary examples of nanotechnology found in the cell. In any other realm of experience, such a complex and delicate arrangement of parts would be immediately recognized as reflecting conscious intent — that is, as being the product of a mind. Why should such an inference be disallowed when examining biological systems? For more detail on this fascinating molecular machine, see my interview on it from last summer on ID the Future. I also published an earlier series (more than a decade ago) exploring the various protein components in more detail. You can find these here:
- “DNA Replication: An Engineering Marvel”
- “Replicating DNA with Extraordinary Fidelity: Meet DNA Polymerase”
- “Unwinding the Double Helix: Meet DNA Helicase”
If you enjoyed the animation by Drew Berry at the beginning of this article, here is a more detailed animation, produced by Oxford University Press. Here is a second animation which reveals how the DNA polymerases are coupled so that they can move in the same direction.
Notes
- McCarthy D, Minner C, Bernstein H, Bernstein C. DNA elongation rates and growing point distributions of wild-type phage T4 and a DNA-delay amber mutant. J Mol Biol. 1976 Oct 5;106(4):963-81.
- Schaaper RM. Base selection, proofreading, and mismatch repair during DNA replication in Escherichia coli. J Biol Chem.1993 Nov 15;268(32):23762-5.
- Baker TA, Bell SP. Polymerases and the replisome: machines within machines. Cell. 1998 Feb 6;92(3):295-305.
- Leipe DD, Aravind L, Koonin EV. Did DNA replication evolve twice independently? Nucleic Acids Res. 1999 Sep 1;27(17):3389-401.
- Brown JR, Doolittle WF. Archaea and the prokaryote-to-eukaryote transition. Microbiol Mol Biol Rev. 1997 Dec;61(4):456-502.